Introduction
本文为斯坦福大学CS231n课程作业及总结,若有错误,欢迎指正。
所有代码均已上传到GitHub项目cs231n-assignment1
Code
1. 通过循环计算Loss和梯度
实现思路: 与SVM类似,计算loss和grad,损失函数如下:
$L i=-\log \left(\frac{e^{f_{y_{i}}}}{\sum_{j} e^{f_{j}}}\right)$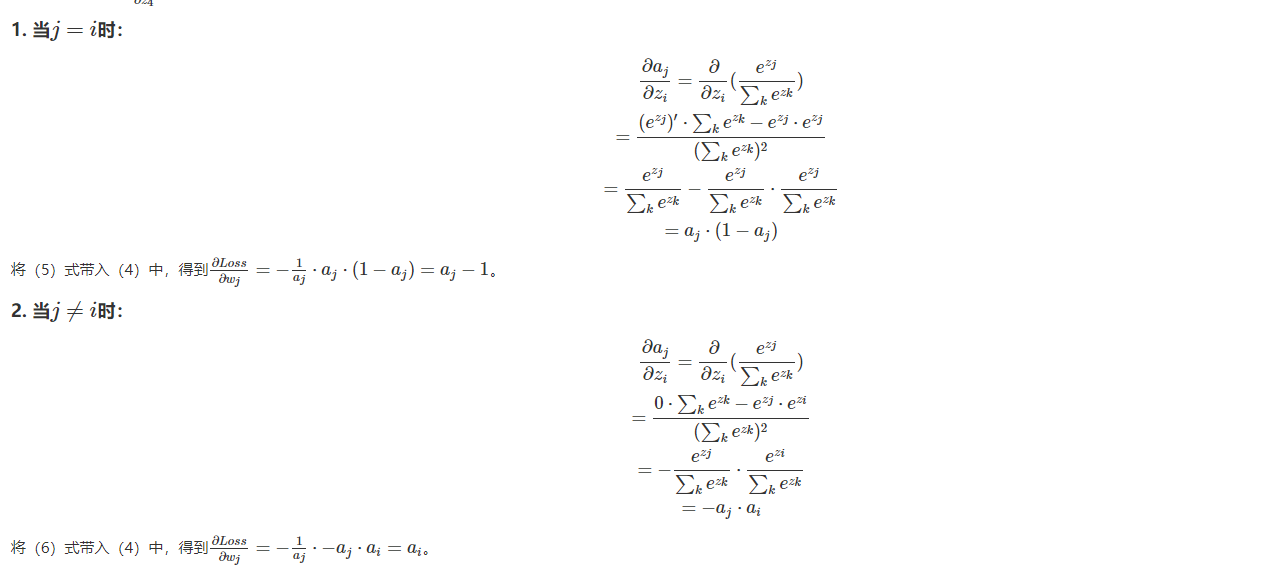
def softmax_loss_naive(W, X, y, reg):
"""
Softmax loss function, naive implementation (with loops)
Inputs have dimension D, there are C classes, and we operate on minibatches
of N examples.
Inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels; y[i] = c means
that X[i] has label c, where 0 <= c < C.
- reg: (float) regularization strength
Returns a tuple of:
- loss as single float
- gradient with respect to weights W; an array of same shape as W
"""
# Initialize the loss and gradient to zero.
loss = 0.0
dW = np.zeros_like(W)
#############################################################################
# TODO: Compute the softmax loss and its gradient using explicit loops. #
# Store the loss in loss and the gradient in dW. If you are not careful #
# here, it is easy to run into numeric instability. Don't forget the #
# regularization! #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_train = X.shape[0]
num_classes = W.shape[1]
for i in range(num_train):
scores = X[i].dot(W)
shift_scores = scores - max(scores)
loss_i = - shift_scores[y[i]] + np.log(sum(np.exp(shift_scores)))
loss += loss_i
for j in range(num_classes):
softmax_output = np.exp(shift_scores[j])/sum(np.exp(shift_scores))
if j == y[i]:
dW[:,j] += (-1 + softmax_output) *X[i]
else:
dW[:,j] += softmax_output *X[i]
loss /= num_train
loss += 0.5* reg * np.sum(W * W)
dW = dW/num_train + reg* W
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW2. 实现svm_loss_vectorized 函数
实现思路:
- 主要使用向量化解决,计算loss灵活应用整型访问和广播机制,计算grad灵活应用矩阵乘法,通过构造矩阵乘法免去累加和循环
- 灵活使用
[range(num_train), list(y)]
def softmax_loss_vectorized(W, X, y, reg):
"""
Softmax loss function, vectorized version.
Inputs and outputs are the same as softmax_loss_naive.
"""
# Initialize the loss and gradient to zero.
loss = 0.0
dW = np.zeros_like(W)
#############################################################################
# TODO: Compute the softmax loss and its gradient using no explicit loops. #
# Store the loss in loss and the gradient in dW. If you are not careful #
# here, it is easy to run into numeric instability. Don't forget the #
# regularization! #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_train = X.shape[0]
num_classes = W.shape[1]
scores = X.dot(W)
shift_scores = scores - np.max(scores,axis=1).reshape(-1,1)
softmax_output = np.exp(shift_scores)/np.sum(np.exp(shift_scores), axis = 1).reshape(-1,1)
#loss = np.sum(-shift_scores[range(num_train),list(y)].reshape(-1,1) + np.log(np.sum(np.exp(shift_scores),axis=1).reshape(-1,1)))
loss = -np.sum(np.log(softmax_output[range(num_train),list(y)]))
loss = loss / num_train + 0.5 * reg * np.sum(W * W)
dS = softmax_output.copy()
dS[range(num_train),list(y)] -=1
dW = (X.T).dot(dS)
dW /= num_train
dW += reg * W
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW3. 计算多个学习率和正则化强度的准确率
实现思路:
- 两次循环计算即可
################################################################################
# TODO: #
# Use the validation set to set the learning rate and regularization strength. #
# This should be identical to the validation that you did for the SVM; save #
# the best trained softmax classifer in best_softmax. #
################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
for learning_rate in learning_rates:
for regularization_strength in regularization_strengths:
softmax = Softmax()
loss = softmax.train(X_train, y_train, learning_rate=learning_rate, reg=regularization_strength
, num_iters=1000, verbose=True)
y_train_pred = softmax.predict(X_train)
train_accuracy = np.mean(y_train == y_train_pred)
y_val_pred = softmax.predict(X_val)
val_accuracy = np.mean(y_val == y_val_pred)
results[(learning_rate,regularization_strength)]=(train_accuracy,val_accuracy)
if val_accuracy > best_val:
best_val = val_accuracy
best_softmax = softmax
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****4. 多个学习率和正则化强度可视化结果

Summary
本次作业主要是对于softmax的应用,总体与svm类似,主要难点在于梯度的推导与计算。
需要着重掌握numpy中数组的操作,灵活实现向量化运算。


